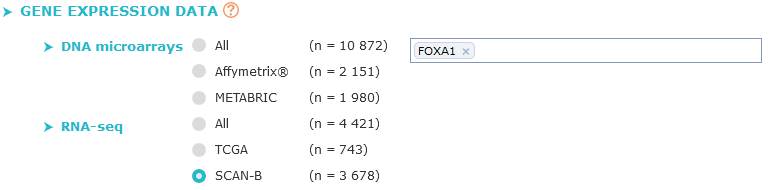| Breast Cancer Gene-Expression Miner v5.0
(bc-GenExMiner v5.0) | |  |
Tutorial - Customised expression analysis
|
|
Customised expression analysis permits to screen the expression level of a gene according to
another gene by dichotomizing the latter (based on median value) and taking the resulting binary value as criterion.
|
|
|
| Step one |
Criterion 1:
gene expression data
First choose the data source (All DNA microarrays, METABRIC, TCGA...), then fill the first textbox with actualised* gene symbol (at least 2 characters must be entered)
or
Affymetrix® probeset ID.
A dropdown list will appear, you can then select the gene you want to test (called gene A), this is the gene whose distribution will be studied.
The list of available genes depends on the previously chosen data source,
if any option, except "Affymetrix®", is checked only gene symbols available with selected data are shown in list.
If "Affymetrix® platform" is checked only gene symbols represented by a probeset are listed. In particular for this analysis module, only probes from the U133 Plus 2.0 array are available.
Each probeset can be selected, if there is more than one probeset, three additional options are available:
- Median probe: median value of all probesets corresponding to the selected gene is taken,
- Highest probe: the probeset having the highest expression level is retained for the analysis (highest median value in a majority of U133P2 and U133A datasets;
in case of ties, decision was based on the total number of patients in the cohorts.),
- JetSet probe: probeset with the highest score given by
JetSet algorithm.
*: see actualised web databases (e.g.:
Ensembl,
GeneCards,
HGNC,
NCBI Gene...)
Then fill the second textbox with another actualised* gene symbol (called gene B), this gene will be your criterion to split your gene A in two groups.
The same type of gene A expression data will be used for gene B automatically, you do not have to select data type.
Criterion 2:
endpoint
Choose the kind of discretisation used for correlation analyses as a splitting criterion:
- median,
- tertile,
- quartile,
- optimal: gene or probeset is split according to all percentiles from the 20th to the 80th, with a step of 5,
and the cutoff giving the best p-value (Welch's test) is kept,
- customised percentile: choose any percentile from the 20th to the 80th, with a step of 1, to dichotomise the gene.
Last criterion: output figure
Each expression plots can be viewed and saved in several formats
To optimize calculation time, only one type of figure will be generated, all are available but only one type at a time.
You have to choose which figure you will get at the results page, by clicking on the appropriate button.
You can preview the type of figure by clicking on the eye logo, a sample will be displayed.
Once all the criteria have been chosen, click on "Submit".
|
Step two |
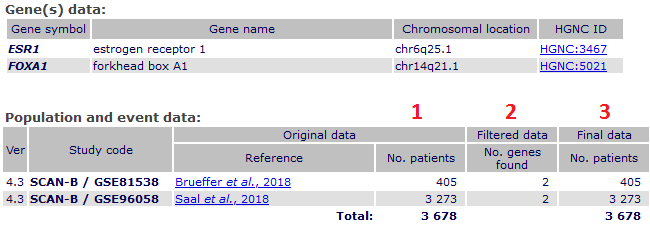
Validation of analysis plan.
After submission, a validation page shows detailed information about tested genes and:
- number of patients from original studies tested,
- 1 complete data before filtering;
2 if the gene is found or not;
and 3 patients finally analysed (if the two genomic data is present for a same patient).
|
|
|
After visualising the validation screen and reading the summary, at the bottom of the page, you can then choose to validate or cancel your submission according
to these intermediate descriptive data summarized at the bottom of the page.
- "Start analysis" will launch
statistical analyses
with the chosen gene and direct you to expression analysis result page.
- "Cancel" will redirect you back to previous screen, and offer you to choose a new gene.
|
|
|
|
Results are displayed with the choosen plot (here raincloud) showing distribution of gene A expression according
to optimized-dichotomised (here 80th percentile) expression of gene B. All the types of plots available are:
- box and whisker,
- bee swarm,
- violin,
- and raincloud.
Click on the "plot" button to display or hide the chosen figure. (In this tutorial raincloud plot was selected)
|
|
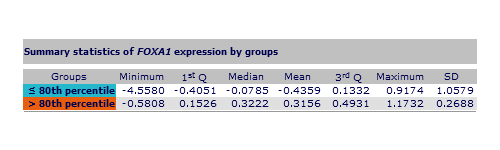
Additionally, a table displays summary statistics data like minimum, 1st quartile, median, mean, 3rd quartile, maximum and standard deviation for each group.

|
Each expression plots can be saved in "PNG" ([portable network graphics] an universal and easy to use format) or
"SVG" ([scalable vector graphics] a lossless image format figure that allows edit viewing and printing settings, as you wish, for your research article) format. |
|
|
|
|